








Microsoft introduces text-to-speech avatar tool in deepfake era
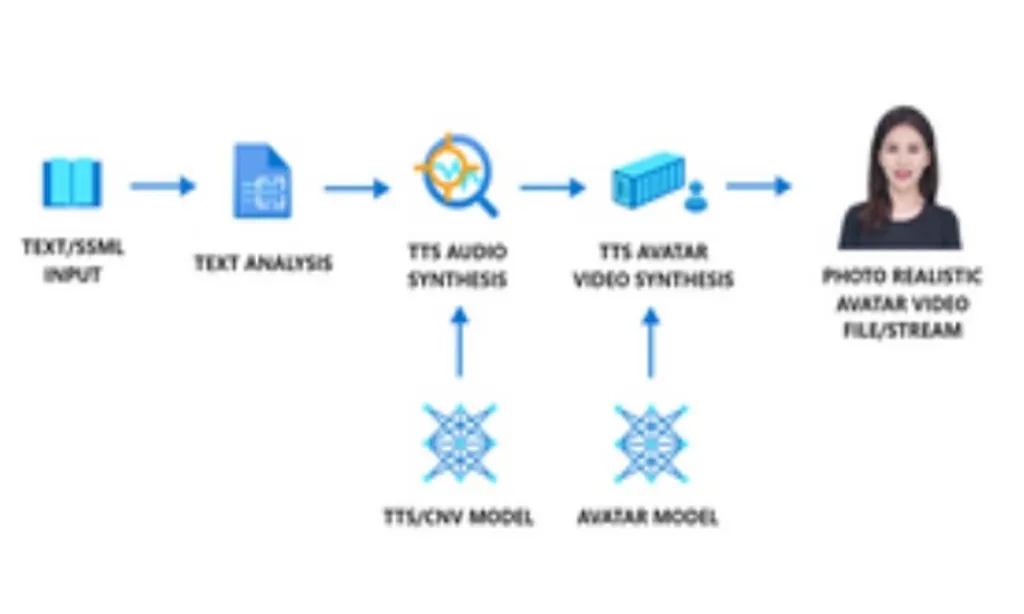
San Francisco: Microsoft has introduced a new text-to-speech feature with vision capabilities, enabling users to create talking avatar videos with text input and create real-time interactive bots trained using human images. It’s called Azure AI SpeechText and is available in public preview, allowing customers to create synthetic videos of a 2D photorealistic avatar speaking.
“The neural text-to-speech avatar model is trained by deep neural networks based on human video recording samples, and the avatar voice is provided by a text-to-speech voice model,” the company said during a late-night ‘Microsoft Ignite’ event. Is.” Wednesday. With text to speech avatars, users can create more engaging digital interactions. They can use avatars to create conversational agents, virtual assistants, chatbots, and more.
Text-to-speech avatars are designed with the intention of protecting the rights of individuals and society, promoting transparent human-computer interaction, and countering the spread of harmful deepfakes and misleading content. “For this reason, custom avatars are a limited access feature that is available only by registration and only for certain use cases.
To access and use the feature in your business applications, register your use case here and apply for access,” the company said. The company is currently offering two different text-to-speech avatar features: prebuilt text-to-speech avatars and custom text-to-speech avatars. “Microsoft offers prebuilt text-to-speech avatars as out-of-box products on Azure for its customers. These avatars can speak different languages and voices depending on text input. Customers can select an avatar from a variety of options and use it to create video content or interactive applications with real-time avatar reactions,” the company said.





